Primary Key
A primary key is defined to identify in a unique way, a set of columns in a table
A primary key has the following specifications:
- NOT NULL
- UNIQUE
Foreign Key
A foreign key is made with one or several corresponding columns of a primary Key:
- To ensure junction between tables and find the corresponding information in a child table (I can reference someone in my Primary table by affecting a number, and I can find a corresponding information in a secondary table by reading all the rows with the same number)
- To ensure the referential integrity (I can not delete a record in my primary table if corresponding information still exists in my secondary table)
Integrity Constraint – Natural keys vs surrogate keys
Natural keys
Natural keys are made with columns involved for the need of users, within you insert / modify data.
Finding a natural key means you choose one or several columns : a social ID is by definition unique and not null and is a perfect candidate for being a primary natural key. This particular case works when you are managing people in a table linked to other dependent tables.
Unfortunately, you sometimes manage other informations and finding a natural key, can easily become a nightmare : you often need to compose you key of different types of information, if you respect the ACID rules when you create your database (Atomicity, Consistency, Integrity, Durability)
Surrogate keys
A surrogate key is a key you just made up without any connection with the real data in the database(generally an integer or bigint). By definition, this key is only used to link tables together, but never used directly by the user.
This key are generated most often on one column wether code side (I wouldn’t advise this technic, I will explain why later in this article), or SQL Server side (that is the best choice)
How to choose a type of data for your keys
As we saw previously, the best way to manage a primary key / foreign key is to choose between auto incremented INT or BIGINT.Everything depends on the amount of rows you will have to manage within a single table and the environment within you are running your database.
In a 32bit environment
Do you remember what is a 32bit environment ? It means your system runs with a processor that is able to treat 32bit of data in one clock cycle. If you remember well a computer is cadenced by a clock (value given by the vendors ie 2.8Ghz) that gives the number of time the processor can use its components (buses, piles, accumulator,…) in one second. 32bit represent 4 bytes (1 byte is 8 bit)
An INT is calculated on 4bytes and so can store 2p32 that means can generated an unsigned number between 0 to 4,294,967,295 (which equals to 232 − 1) that means 4 billions of different numbers! more than enough to manage the whole employees of a company, the salaries, the invoices, even phone numbers of whole people on earth…
In a 32bit environment, an INT perfectly fits with the size of the processor (in one clock cycle, a 4 bytes processor or 32 bit processor can generate / use a 4bytes INT or 32bit INT
In a 64bit environment
Same application for 64 environment : 64bit = 8 bytes
A BIGINT is composed of 8 bytes and can adress an unsigned number from 0 to 18,446,744,073,709,551,615 which equals to 264 − 1. You can generate a BIGINT in one clock cycle and manage it in the same way. This size perfectly fits with the 64bit system
Uniqueidentifier
It’s trendy now to use a lot of uniqueidentifiers in databases. It’s a kind of ‘magic wand’ that allows you to manage a huge amount of data and identify each one in a unique way. The uniqueidentifier can warranty its uniqueness by basing the generated ID on the network card mac address and random operations on the CPU Clock
SELECT NEWID() AS UNIQUEIDENTIFIER
UNIQUEIDENTIFIER
086666BB-FE3E-4CDC-9827-2A5EE3949BF6
An uniqueidentifier is made of 16 bytes. As you can guess, following the previous rules, a uniqueidentifier will need two clock cycles on a 64 bit (or 4 clock cycles on a 32bit environment) to be generated. obviously, it’s not an optimized type for primary keys/foreign keys for a table in order to identify common data.
The only exception you can imagine is linking two different databases that really need uniqueness. The SQL Server Merge Replication uses this data type to link :
- the table you have created and
- the merge tables installed when you publish some articles on your database.
The merge replication by default do not use your primary keys but add a new column called ROWGUID with a uniqueidentifier type. The triggers are fired each time you insert a data within an implicit or explicit transaction in your table and use this ROWGUID Columns to link with the ID of the merge table.
Comparison between a few type of surrogate keys and natural keys
We will create here some table in a database in order to fulfill then with data and analyse different criterias like:
- Number of reads
- Number of writes
- page count
- Percentage of average space used in pages
- Percentage of fragmentation in pages
-- INT IDENTITY
CREATE TABLE [dbo].[TESTTABLE_INT](
[ID] [int] IDENTITY(1,1) NOT NULL,
[FirstName] [char](10) NOT NULL,
[LastName] [char](20) NOT NULL,
[Job] [char](15) NULL,
PRIMARY KEY CLUSTERED
(
[ID] ASC
))
-- BIGINT IDENTITY
CREATE TABLE [dbo].[TESTTABLE_BIGINT](
[ID] [bigint] IDENTITY(1,1) NOT NULL,
[FirstName] [char](10) NOT NULL,
[LastName] [char](20) NOT NULL,
[Job] [char](15) NULL,
PRIMARY KEY CLUSTERED
(
[ID] ASC
))
-- UNIQUEIDENTIFIER NEWID
CREATE TABLE [dbo].[TESTTABLE_NEWID](
[ID] [uniqueidentifier] DEFAULT (newid()) NOT NULL,
[FirstName] [char](10) NOT NULL,
[LastName] [char](20) NOT NULL,
[Job] [char](15) NULL,
)
-- UNIQUEIDENTIFIER NEWSEQUENTIALID
CREATE TABLE [dbo].[TESTTABLE_NEWSEQUENTIALID](
[ID] [uniqueidentifier] DEFAULT (newsequentialid()) NOT NULL PRIMARY KEY CLUSTERED,
[FirstName] [char](10) NOT NULL,
[LastName] [char](20) NOT NULL,
[Job] [char](15) NULL,
)
CREATE TABLE [dbo].[TESTTABLE_NATURALKEYS](
[FirstName] [char](10) NOT NULL,
[LastName] [char](20) NOT NULL,
[Job] [char](15) NOT NULL,
PRIMARY KEY CLUSTERED
(
[FirstName] ASC,
[LastName] ASC,
[Job] ASC
))
Now we generate data in the differents table with the following script:
PROCEDURE [dbo].[sp_GenerateRandomString]
(
@intGENERATEDSIZE INTEGER
,@strGeneratedString VARCHAR(30) OUTPUT
)
AS
DECLARE @REFERENCE AS VARCHAR(63)
DECLARE @intREFERENCESIZE AS INTEGER
DECLARE @strWORD AS VARCHAR(30)
DECLARE @Letter CHAR(1)
SET @REFERENCE = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz1234567890'
SET @intREFERENCESIZE = len(@REFERENCE);
SET @strWORD =''
WHILE @intGENERATEDSIZE > 0
BEGIN
SET @Letter = SUBSTRING(@REFERENCE, CONVERT(INT,(RAND() * @intREFERENCESIZE))+1, 1);
SET @strWORD = @strWORD + @Letter
SET @intGENERATEDSIZE = @intGENERATEDSIZE -1;
END;
SET @strGeneratedString = @strWORD
Now we can insert 20 000 rows in each table
DECLARE @COUNT INT;
SET @COUNT = 0;
DECLARE @strFirstName VARCHAR(10)
DECLARE @strLastName VARCHAR(20)
DECLARE @strJob VARCHAR(15)
WHILE @COUNT < 20000
BEGIN
exec sp_GenerateRandomString 20 , @strFirstName OUTPUT
exec sp_GenerateRandomString 20 , @strLastName OUTPUT
exec sp_GenerateRandomString 20 , @strJob OUTPUT
INSERT dbo.TESTTABLE_NATURALKEYS
(
FirstName
,LastName
,Job
)
VALUES
(
@strFirstName
,@strLastName
,@strJob
)
SET @COUNT = @COUNT + 1;
END;
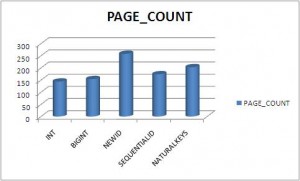
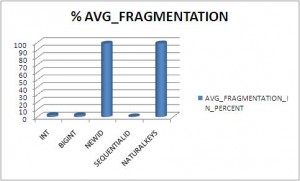
Here are the graphical results:
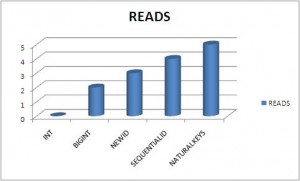
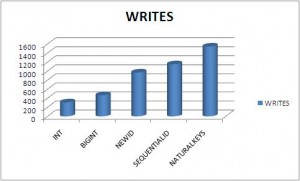
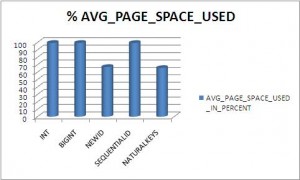
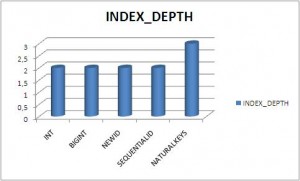
{kind=link}
Conclusion
As you can guess the winner is : INT !!! Below the order of data types, you should prefer, for your primary / foreign keys:
- INT
- BIG INT
- UNIQUEIDENTIFIER (with a default value as NEWSEQUENTIALID)
- UNIQUEIDENTIFIER (with a default value as NEWID)
- NaturalKeys
The worses are the UNIQUEIDENTIFIER with NEWID and NaturalKeys that cause :
- a huge split of pages (page count),
- a huge increase of reads and writes (ie logical IO’s)
- the lowest usage of space in each page
- the highest split of data in pages (% of fragmentation)