After practicing replication on SQL Server, it appears to me like a non sense to publish directly your tables if you plan to have a heavy work load and a lot of changes in your database.
I had to maintain and try to improve a replicated database that contains data changing every 3 days.
That means, every 3 days the complete content is renewed: you can imagine the amount of data and operations involved by the replication triggers after inserts or updates or deletes
During these upserts, thousands of PDA are merging and getting data through 3G network.
We met contentions on the database because threads involved in the merge with PDA were locked by the insertions.
In other words with a lot of renewing and a lot of merges you can encounter problems. Plus at a certain point you need to be really carefull with the metadata tables and monitor them to avoid a huge growth of these tables (ie msmerge_past_partition_mappings and msmerge_current_partition_mappings)
One way is to scale out your replication but you need to had some material and infrastructure.
Splitting upsets and merges
You usually develop your database using relational schema and ACID rules that is a good thing for every OLTP applications.
The point is, by publishing directly these tables, you add replication triggers (on top of system tables) on each table published and with an heavy load (Insertions / updates / deletes) plus a lot of concurrent merges, you often have to deal with locks, deadlocks sometime and an impossibility to increase your load.
You need to understand the utility of de-normalization here (even if DBAs do not usually agree with that and everything here blows the best practices away). A good example of how you can do that can be illustrated by what happens by using views.
These views build virtual tables (or physical tables if they are indexed) that concentrate information from several tables (generally 2 or 3) , based on queries with joins between them.
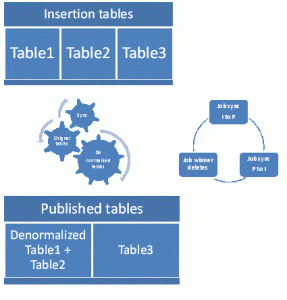
You can imagine now having these views as physical tables, and publishing them.
Now you need to make a link between your original tables and your published tables.
You can do that easily by creating jobs launched every x minutes in order to manage the differences between your original tables and the published tables. These jobs will call stored procedures (insertion / updates )
Splitted Merge – denormalization Schema
Database ad table creation
First of all we create a database called UpsertDB.
In this database we create 2 tables and load some data.
CREATE TABLE [dbo].[Subscribers](
[ID] [uniqueidentifier] DEFAULT (newsequentialid()) NOT NULL PRIMARY KEY CLUSTERED,
[FirstName] [char](10) NOT NULL,
[LastName] [char](20) NOT NULL,
[Job] [char](15) NULL, )
CREATE TABLE [dbo].[Subscribers_Main](
[ID] [uniqueidentifier] DEFAULT (newsequentialid()) NOT NULL PRIMARY KEY CLUSTERED,
[FirstName] [char](10) NOT NULL,
[LastName] [char](20) NOT NULL,
[Job] [char](15) NULL, )
INSERT INTO [Subscribers]
(
FirstName,
LastName,
Job
)
VALUES
('Marcel', 'Patoulacci', 'A'),
('Bob', 'Robichais', 'B');
INSERT INTO [Subscribers_Main]
(
FirstName,
LastName,
Job
)
VALUES
('JP', 'Veedole', 'C')
SELECT * FROM Subscribers
ID FirstName LastName Job 24BEF86E-0660-E211-9EA0-1CC1DE741410 Marcel Patoulacci A 25BEF86E-0660-E211-9EA0-1CC1DE741410 Bob Robichais B
SELECT * FROM Subscribers_Main
ID FirstName LastName Job 9DBB1C2B-0760-E211-9EA0-1CC1DE741410 JP Veedole C
Creating an upsert procedure
The content of your procedure could look like this:
USE [UpsertDB] GO --Upsert from Subscribers to Subscribers_Main MERGE INTO dbo.Subscribers_Main AS T USING dbo.Subscribers AS S ON T.ID = S.ID -- When IDs are found in both tables -- Then we update Subscribers_Main -- with Subscribers rows WHEN MATCHED THEN UPDATE SET T.FirstName = S.FirstName, T.LastName = S.LastName, T.Job = S.Job -- When IDs are not in Subscribers_Main -- Then we insert into Subscribers_Main -- all missing Subscribers rows WHEN NOT MATCHED THEN INSERT ( ID, FirstName, LastName, Job ) VALUES ( S.ID, S.FirstName, S.LastName, S.Job );
Results and requirements
Keep in mind that you must force to insert IDs.
If you miss it, the ID column will generate a new ID by default, of course different the ID of the original table.
In this case you won’t be able to find the real new values next time and you take a risk of inserting several times the same values.
You can check this requirement by selecting the Subscribers_Main table:
ID FirstName LastName Job 24BEF86E-0660-E211-9EA0-1CC1DE741410 Marcel Patoulacci A 25BEF86E-0660-E211-9EA0-1CC1DE741410 Bob Robichais B 9DBB1C2B-0760-E211-9EA0-1CC1DE741410 JP Veedole C
and look at the result without insertion of IDs (ID values coming from the subscribers table are different than before because they are automatically generated during their insertion) :
ID FirstName LastName Job 9DBB1C2B-0760-E211-9EA0-1CC1DE741410 JP Veedole C E66CE936-0A60-E211-9EA0-1CC1DE741410 Marcel Patoulacci A E76CE936-0A60-E211-9EA0-1CC1DE741410 Bob Robichais B
Going further
Now you just have to implement your management rules for deletes and decide who is the winner if a row exists in the Subscribers table and not in the Subscribers_Main table.